
ChatGPT undermines the case for human irrationality
It makes the same "errors" as humans—suggesting that they may be symptomatic of optimized domain-general reasoning

TLDR: Humans make systematic errors: apparent overconfidence, the conjunction fallacy, the gambler’s fallacy, and belief inertia. For decades, this has been taken to show that we reason in an irrational, non-probabilistic way. But GPT4—an optimized probabilistic reasoner—exhibits every one of these “errors”. Humans may be smarter than we thought.
Charlie is a helpful chap. An experimenter’s dream subject, really. He knows a lot. Ask him any question you like, and he’ll try his best to answer it.
But sometimes he’s wrong. Indeed—as with most people—when he has to make judgments under uncertainty, his errors tend to be systematic.
He seems to display overconfidence: his average confidence in his guesses often exceeds the proportion of those guesses that are correct—on a typical test, his average confidence was 73% but his proportion-correct was only 53%.
He commits the conjunction fallacy: often saying that conjunctions (A&B) are more probable than their conjuncts (A)—contrary to the laws of probability.
He commits the gambler’s fallacy: if a coin lands tails a few times in a row, he tends to act as if a heads is “due”.
He displays both conservativeness and belief inertia when updating on (for example) random draws from an urn: he does not update as much as a Bayesian would, and once he becomes confident of a claim, he’s too slow to respond to evidence that undermines it.
Given all that, what do you conclude about how Charlie deals with uncertainty?
Perhaps—following some heroic psychologists and philosophers—you’d argue that these “errors” are in fact “resource-rational” responses given his limited information and cognitive resources. Maybe his “overconfidence” is largely due to selection effects. Maybe the conjunction fallacy results from a sensible tradeoff between accuracy and informativity. Maybe the gambler’s fallacy arises from reasonable uncertainty about the causal system. And maybe conservativeness is due to ambiguity in the experimental setup.
Maybe.
But that’s a bit forced, isn’t it? You’re probably more inclined to follow behavioral economists, concluding that these errors provide strong evidence that Charlie is irrational. Rather than maintaining complex probability distributions, he must use other (worse) ways of handling uncertainty—such a simple heuristics that lead to these systematic biases.
You’re wrong.
For “Charlie” is ChatGPT. GPT4, in fact: a trillion-parameter large language model that we know reasons in a fundamentally probabilistic way. It aces our hardest exams, can write code like a programmer, and is the closest we’ve come to a domain-general reasoner. And yet it readily exhibits the overconfidence effect, the conjunction fallacy, the gambler’s fallacy, and belief inertia.
Those effects some of the strongest bits of evidence that have been marshaled to suggest that humans handle uncertainty in an irrational, non-probabilistic way. The fact that ChatGPT also exhibits them casts major doubt on that irrationalist narrative, and speaks in favor of the “resource-rational” alternative that initially seemed forced.
Here’s why.
Overconfidence
The finding: The classic way psychologists have tried to get evidence about whether people are overconfident is with “2-alternative forced choice” tasks: people are forced to guess which of two alternatives they think is most likely, and then rate their confidence (between 50–100%) in those guesses. The “overconfidence effect” is the finding that—very often, especially with hard questions—people’s average confidence exceeds their proportion correct.
ChatGPT’s results: Taking a standard methodology from the literature, I asked ChatGPT to guess which of a set of pairs of American cities had a larger population (in the city proper).
Its average confidence in its guesses was 73.3%, but its proportion correct was 52.9%. The difference is statistically significant.1 (The trick is to ask it for pairs that are close to each other in the ranking.)
The Conjunction Fallacy
The finding: The classic example of the conjunction fallacy describes Linda:
Linda is 31 years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in antinuclear demonstrations.
Subjects were then asked which they think is more likely:
Linda is a bank teller.
Linda is a bank teller who is active in the feminist movement.
85% of people chose option (2). But this is an error in probabilistic reasoning: as we can see with the Venn diagram, every possibility in which Linda is a feminist bank teller is also one in which she’s a bank teller; so the latter (a conjunction, A&B) can’t be more probably than former (a conjunct, A)—no matter how probable feminist is.
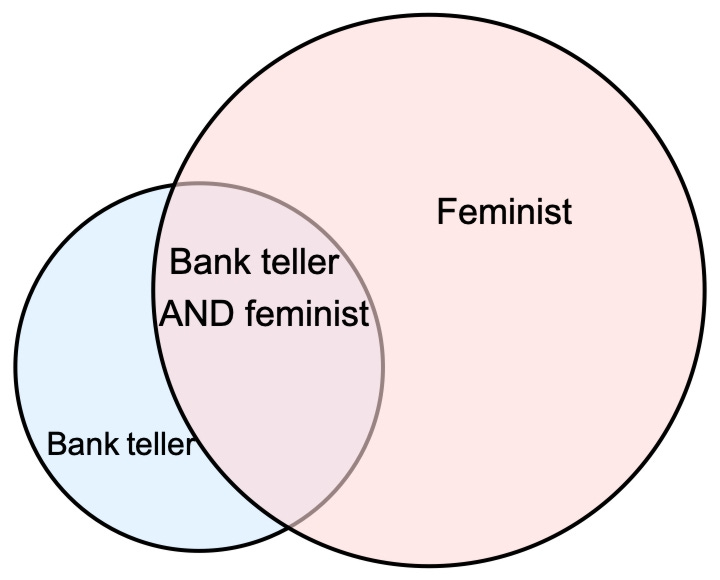
ChatGPT’s results: if you give ChatGPT more-or-less the exact same wording, it’ll catch on and realize this is a test of the conjunction fallacy. But vary the case ever so slightly, and it’ll fall for the conjunction fallacy:

And it’s not just this version of the case. Like people, ChatGPT also will commit the conjunction fallacy when no relevant evidence is presented or when one option is a disjunction (A or B) and the other is a disjunct (A).
The Gambler’s Fallacy
The finding: The gambler’s fallacy is the tendency to think that random processes tend to “switch”—thinking that after a streak of tails (like THTTTT), a heads is “due” in order to balance out the sequence. In fact, it’s not: a random (fair) coin has no memory, so each toss is exactly 50%-likely to be a tails, regardless of the past tosses.
What is true is that the “law of large numbers” implies that in the long run, roughly 50% of the (fair) tosses will land heads—so if you wait long enough, it’s very likely that the overall proportion will return toward 50%. But that’s because there are more possibilities in which a long string has roughly 50% Hs and Ts than ones in which it doesn’t.2 This long-run effect has no influence on the next toss—there are exactly two equally-likely possibilities for that—H and T. For that reason, the gambler’s fallacy is sometimes called a fallacious belief in the “law of small numbers”.
The most well-studied way to elicit this fallacy is with production tasks: ask people to produce hypothetical outcomes from a fair coin, and then observe the statistical features of the outcomes they generate.
People are bad at this. The sequences they generate tend to switch (from heads to tails, or tails to heads) around 60% of the time—rather than the true rate of 50%. Moreover, the proportion of sequences that switch grows dramatically as the streak gets longer, as can be seen in the following table from this paper:

After a sequence of HHT, the probability of switching to heads is 48.7%; after HTT, it’s 62%; after TTT, it’s 70%.
ChatGPT’s results: ChatGPT behaves remarkably similarly. I asked it to generate 5 sequences of 100 results from a fair coin, and the switching rate was 60.8%. Here’s one of those sequences:
1,0,1,0,0,1,1,0,0,1,0,0,0,1,1,0,1,0,0,1,1,1,0,1,0,1,1,0,0,0,1,0,1,1,0,1,0,0,0,1,0,1,0,0,1,0,1,1,0,0,1,0,1,1,0,1,1,0,1,0,0,0,1,1,1,0,0,1,1,0,0,1,0,1,0,1,0,0,1,0,1,1,1,1,0,1,1,0,1,1,0,0,1,1,0,0,0,1,1,0,1,0,1,1,0,1,0
As you can see from a glance, it switches far too often. Moreover, the switching rate also increases dramatically with streak length. Here are the rates of switching, by streak length, from all 500 of the outcomes I had it generate:
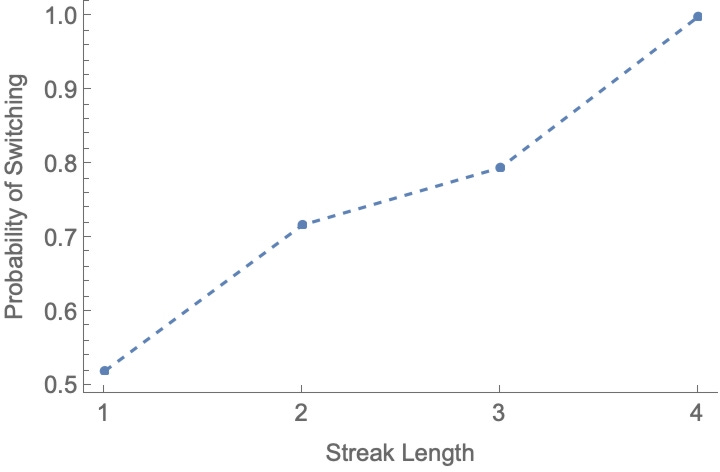
After a streak of 1, it’s 52% likely to switch; after 2, it’s 72% likely after 3, it’s 79% likely; after 4, it’s 100% likely.3
Conservativeness and Belief Inertia
The findings: Conservativeness is the finding that people don’t update as much as a Bayesian would when they learn from the outcomes of a random process. Belief inertia—a form of confirmation bias—is the finding that once people form a belief in this way, they are too slow to revise it when new evidence should undermine that belief.
The classic way to demonstrate these findings is to draw marbles (with replacement) from a bag of unknown composition. Tell people that a randomly-selected bag is either mostly-red (2 red, 1 green) or mostly-green (1 red, 2 green). Then draw a sequence of marbles.
After 3 marbles in a row, a Bayesian would jump from 50% to 94%-confident that it’s the mostly-red bag, while real people tend to be in the 80–90% range. That’s conservativeness.
And if you give people a sequence that starts out heavily favoring one bag (to induce a belief), but then later balances out, people don’t revise their beliefs back down to 50% the way they should. For example, consider the following “red first” sequence:
red, red, red, red, red, red, green, green, red, red, red, green, green, green, red, green, green, green, green, green
Given this sequence, people wind up more than 50%-confident the bag is mostly-red, despite the fact that it has the same total number of reds and greens (10 each). Conversely, if we swap “green” and “red” to make a green-first sequence, people wind up less than 50%-confident the bag is mostly red. That’s belief inertia.
ChatGPT’s result: Here are the results of giving it the “red first” and the “green first” sequences, comparing how it’s beliefs evolve to that of a Bayesian:
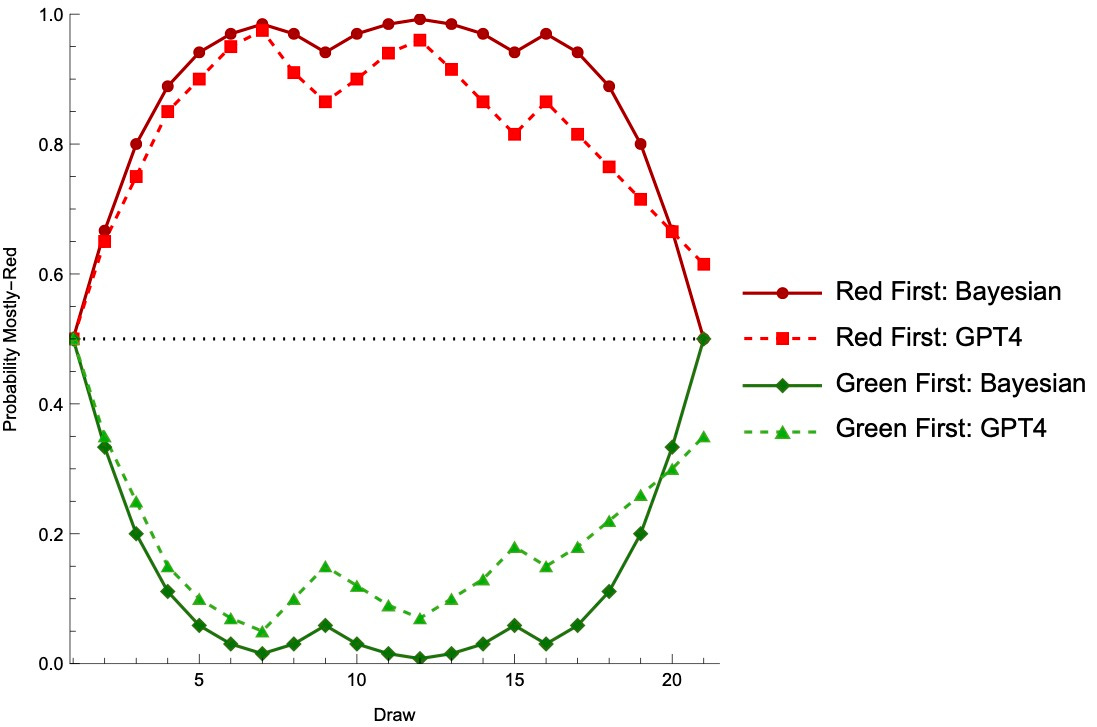
ChatGPT displays both conservativeness and belief inertia. Conservativeness can be seen from the fact that the dashed curves are shallower than the solid (Bayesian) curves. Belief inertia can be seen from the fact that the “red first” sequence led it to be 61.5%-confident of mostly-red, while the “green first” sequence led it to be 35%—when in fact, both should’ve ended at 50%. (A gap of 26.5% probability given what should be equivalent evidence!)
What does this mean?
GPT4—an extremely optimized, probabilistic, domain-general reasoning machine—commits the same systematic errors that have been used to argue that humans couldn’t be optimized, probabilistic reasoning machines.
The measured conclusion? It turns out that systems that are fundamentally probabilistic and highly optimized can still be expected to exhibit these errors. At the least, this helps reconcile the above findings with the well-supported result that many low-level processes in the brain—such as visual perception, motor control, and unconscious decision-making—are thoroughly Bayesian.
The radical conclusion? Perhaps these “systematic errors” are actually indicators of optimality and rationality—as the “resource-rational” approaches have been saying all along.
“But wait!”, you might reply. “ChatGPT is learning from us. So maybe it’s just ‘optimized’ to replicate our systematic errors in reasoning. No surprise there. Right?”
Wrong. Though tempting, this hypothesis doesn’t hold water, for it forgets what’s so shocking and exciting about ChatGPT.
The hypothesis would predict that GPT4 should be about as smart as the average internet user. If it were, it’d be scoring at (or below) the median on all our standardized tests; its reasoning, grammar, and coding would be about as good as the median internet user; and no one in their right mind would pay $20/month to be able to talk to it. None of those predictions pan out.
What’s shocking about ChatGPT was that they trained it on babble, and what came out was brilliance. What needs to be reckoned with is that an AI that is shockingly smart performs exactly the same sorts of “errors” that have been taken to show that people are surprisingly dumb.
ChatGPT is smarter than we expected. Maybe we are too.
What next?
“Resource-rational” resources:
Overconfidence: This classic piece, this recent book, and my recent paper.
Conjunction fallacy: This classic criticism, and this paper by me and Matt Mandelkern.
Gambler’s fallacy: this semi-rational model—and stay tuned for a paper follow-up to this old blog post.
Conservativeness and belief inertia: See this big-picture piece on bias research, and this hypothesis about ambiguity in the setup.
18 of 34 correct; bootstrapped 95% confidence-interval for the proportion correct was [35.2%,70.5%], below the average confidence of 73.3%.
For example, there’s only one 4-toss string that has 100% heads—namely HHHH—while there are six that have 50% heads—HHTT, HTHT, THHT, HTTH, THTH, TTHH.
Though the sample size was small (there were only 9 streaks of 4), so this is likely an overestimate of the true rate.
Echoing the other comments: I don't think it is true to say that GPT4 is "optimised" for probabilistic reasoning. It's optimised for next-token prediction, and then for what responses humans like or fit with OpenAI guidelines using RLHF. Even if part of fine-tuning was on reasoning problems with reliable solutions, the underlying training on next-token prediction will still be significantly influencing the responses given by the model. There's a high chance these "biases" are just mimicking human behaviour.
I appreciate and admire all your work! But I don't think this idea holds up.
Bard had some thoughts: https://pastebin.com/2PtVAaGt